Automated UI testing can be tricky and is very easy to do wrong. At SEP we’ve done several projects using TestComplete; it is a nice tool, but the early days were painful. We made every mistake in the book, and learned our lessons the hard way. These days, our TestComplete testing efforts are pretty slick. We’ve figured out how to architecture tests, we’ve developed a fairly extensive toolset of helper scripts, and we’ve discovered many things NOT to do.
When I joined my current project, I was delighted to find myself in familiar territory. This new project uses Squish. Unlike TestComplete, Squish is targeted at a very specific technology – Qt (C++). It is cross-platform, using TCP/IP to talk through a network connection. Despite the differences, Squish is like TestComplete’s cousin; they have very similar paradigms.
The client was new to automated UI testing and their code base was still small. It reminded me of the good old days on my TestComplete projects – they were making the EXACT same type of mistakes we made! So I wondered – how many of these old lessons learned applied here?
In automated UI testing, there is a test script and an Application Under Test (AUT). Most testing tools support several different types of scripts. We wrote our TestComplete scripts using JScript. This current project chose to use Python (a decision I applaud). In both tools, these scripts reference UI objects and perform actions on them. They then look at properties of the objects and verify that the expected behavior occurred.
What happens when the developers of the AUT rename a class? You get a stale reference in your script and have to update it. What happens if this reference is sprinkled throughout your test scripts? You have a LOT of updating to do. This is definitely a code smell or perhaps more appropriately a test smell. If you want your scripts to be robust and easy to maintain, you must isolate what changes.
Luckily, the client had already recognized this, and had a single file with all of their references in it. The problem with this is that every test update touched this file, and there were many merge conflicts. The overlays in the AUT were all structured very similarly. They all had the same OK button, Cancel button, footer, content area – and references to these objects were duplicated for EVERY overlay, all in a single file! It was huge. It was a maintenance nightmare.
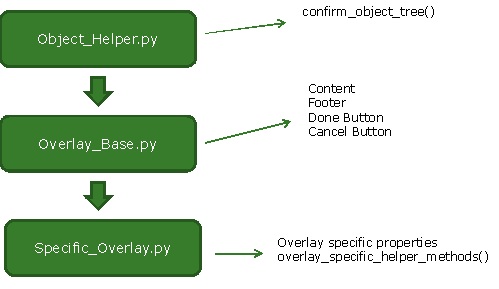
One of our first efforts was to try and break the representation of each overlay (or groups of related overlays) into their own class. We were attempting to take advantage of inheritance by parenting them all off the same base overlay class. Many of the reference details for things like the OK button were the same (same name, same type) but they had different parents. If we have a base overlay class which has all the common elements in it, an object reference file could inherit from this and get all the similar functionality for free without having to duplicate the code. This, in turn, is based on an object helper that can do things like check to make sure all of the object references are valid (useful for finding typos quickly).
This approach greatly diminished the number of merge conflicts as areas were better isolated. We also recognized the need for a better way to check values on objects in the AUT, and so we put in a structure for doing comparisons and a fancy new logger while we were at it.
Never underestimate how awesome it is to have reports that make test results easy to find and make it easy to see patterns in how the tests fail. Some of the reports we came up with really streamlined the process.
At SEP, we realized how vital it is to be able to kick off specific individual tests on demand, so we went about helping to set up a similar system for our client. One of the biggest early wins was the client figuring out how to run tests in parallel farmed out over many machines. One-offs were in high demand, so they added more machines. Finally, we added a feature to be able to kick off specific tests against specific builds on demand, farmed out over enough machines that engineers could get fairly quick feedback.
Occasionally (and especially) when developing automated tests against an application still under development, there are known issues. Sometimes there are assertions that you expect to fail because either the feature isn’t done yet, or the developers haven’t fixed the bug yet. If tasks and bugs are tracked in some external tool like Team Foundation or Rally, you can put the identifying number inside the assertion. When it fails, it can log a Warning against this known and tracked defect. This helps with triage; it is easier to tell when issues are already accounted for. It also helps when developers are doing bug fixes. In an ideal world, when the bug is fixed, the warning disappears. We put this ability into our assertion helper, and we made the result reports reflect the warnings as logged against specific defects.
Another issue the client had was the feedback loop of the tests. The total suites took hours to run, far too long to provide useful information to developers. The failures would go unnoticed and the tests got stale. They needed a way to provide quick feedback and to make sure that developers were paying attention, so we adjusted the build strategy a little bit. We selected a representative subset of the test suites – enough to give a very general “warm fuzzy” feeling that the system was mostly good, like a canary in a mineshaft. These tests run on every check-in. If any test fails, developers can’t check in new code until those tests are fixed. This build is called the “continuous test” (CT) build.
The other suites not in CT weren’t thrown away, but run on a timer as part of a separate build. This is their “Full Regression” (FR) build. The Full Regression build gives feedback when deciding which branch point to release. The suites that are part of these two builds vary based on the needs of the code base at the time. It is more important to test areas under high churn in CT than it is to run a test that has been passing for three months every time code is checked in. As a general rule, failing tests are promoted to CT and soon this will become an automated process.
As developers were working on their features, sometimes they would need to run the tests against their current code. They could do this locally, but it would tie up their machine, take forever, and getting local tests running wasn’t always easy to set up. There was a one-off build for executing these tests, but it was originally hosted on the same machine that the normal build was on, and would grind things to a screeching halt if people started using it during busy times.
The combination of being able to do one-offs before a push, having CT as a gatekeeper for pushing and giving immediate feedback after a push, and having FR as feedback for releasing seems to be a very effective strategy. The code base is growing more and more though, and the tests are getting longer. We’ll have to adjust our strategy to meet the demands.
I’m not sure people realize how challenging a domain automated UI testing is. There are many ways to do it wrong – I’ve only listed a few – and we’re finding new ones all the time. But every once in awhile we find something that makes our lives just a little bit easier, makes our code base just a little bit better. These tests build the robust safety net that allows our developers to go fast with confidence. Don’t give up on automated UI tests, when done right they are more than worth it.
