Let’s elaborate on the nature of these call tree diagrams. Consider the following code:
void doStuff() { doOtherStuff(); } void doOtherStuff() { init(); final(); } void blah( int x ) { if ( x == 2 ) { function(); otherFunction(); } else { doStuff(); } }Depending on the input for the blah function, we are going to experience two very different call graphs. If blah is called with a value of 2 for its input parameter x, then we would see a call tree like:
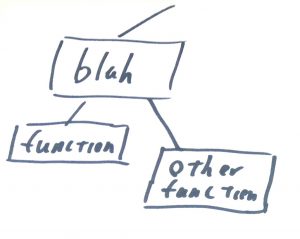
But on the other hand, if blah is called with any other value we end up with a call tree that looks like:
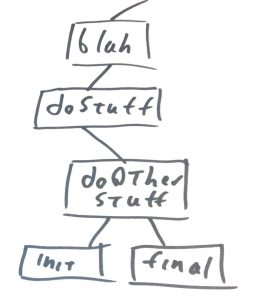
Any given program will potentially have a very large number of corresponding call trees. A call forest if you will. All things being equal, a small call forest is probably more comprehensible than a large one. The idea here is that in order to really understand the program a software engineer will have to understand every call tree in a program’s call forest. This is probably impractical in just about every real world program, so the software engineer will need to construct the program such that understanding a subset of the call trees will yield the necessary insight to effectively work with the program.
Next I want to talk about global variables, but first we need to look into abstract data types.
Build awesome things for fun.
Check out our current openings for your chance to make awesome things with creative, curious people.
You Might Also Like
