
Introduction
People often ask questions like “What is AI?”, or “Is AI worth of the hype?”.Both questions are non-trivial to answer, but let’s start with the first one:”What is AI?”. This is a perennial favorite at academic conferences on AI for a few reasons:
- Every AI researcher has to have an opinion, since it’s their field
- There aren’t clear cut answers, so you can talk about it forever
- Everyone has a version of the same joke: “Whatever machines haven’t done yet”
It’s that last point that’s particularly interesting. The quote is associated with Larry Tessler, but I’ve heard it paraphrased a million times. The thing about AI recently is that once it works repeatedly and reliably, it isn’t AI anymore. This happens because, for better and worse, AI is still seen as a bleeding edge, futuristic thing. The bleeding edge is exciting. There are hard problems and the opportunity that hard problems bring. The bleeding edge is also terrifying. It’s unreliable. It’s expensive. It’s difficult to repair.Understanding the bleeding edge requires a large investment. AI still feels like bleeding edge technology despite decades of research and application.
As a result, researchers move away from the more generic label of AI to a specific field as a way of signaling maturity and reliability. When someone asks me “What can AI do for me?”, I often suspect the answer is “Not much” because it’s the wrong question. If someone asks me “Is there a way to make this free text machinable?” or “Are there better techniques for scheduling these work orders?” the answers are “Yes!” and “Almost certainly.” Are the techniques which solve those problems AI? Absolutely.
Why are the answers so different? It’s the mindset of the person asking the question. “What can AI do for me?” is the wrong question to ask. It’s better to have identified problems and pain points and then ask “Are there AI techniques that can help me address this problem?”. Identifying the provides a framework to answer the question rigorously. A problem definition lets us meaningfully define what is success. Further, it lets us talk about the cost, pitfalls, and known approaches of solving the problem.
All of that still doesn’t answer the question of “What can AI do for me?”.Generally, it can reduce the cost of something you’re already doing or it can provide a capability you don’t already have. How we can achieve either of these outcomes depends on the problem that we need to solve. To get a sense of what’s possible, we’re going to take a look at 5 examples of common AI problems in business.
Scheduling
Scheduling is a frequent problem in the business world. Scheduling problems crop up in the administrative side of the business:
- How do I find a time for many different people to meet?
- What rooms should I put the interviews with the prospective hires in?
- How do I schedule them such that we can run many concurrent interviews that pass people between members of the staff?
Scheduling problems may even be the entirety of the business:
- How do I schedule mechanics to open jobs in my repair shop?
- When can I move this piece of lumber through the board finisher so we can get the product out the door?
Every scheduling problem is unique, but they have the same fundamental core:
- A Set of Things Need to Happen
- They need a resource happen (a room, a machine, a piece of product)
- They need to start after and end before some other event or deadline
It is the fundamental core of the problem that suggests AI. A constraint satisfaction problem is one of assigning values to variables to satisfy a system of equations. Take the problem of finding a schedule of interviews. We might start by considering each hour of the day in a particular room as a variable: Meeting Room A 9 to 10, Meeting Room B from 10 to 11, and so on. Then, we would look for an assignment of interviewers and interviewees to rooms at times such that:
- No interviewer needed to be in two different places at once
- No interviewee needed to be in two different places at once
- No room had two interviewers at the same time
- No room had two interviewees at the same time
- No one was scheduled for more than four consecutive hours
Any assignment that satisfies these is good enough. This is a starting point.There are other metrics for evaluating the quality of the schedules. Maybe we can’t, or don’t want to, capture every constraint in scheduling candidates.People may want to alter suggested schedules manually while still guaranteeing correctness. Each of these modifications shows a possible extension of the base scheduling problem. All of these approaches start with recognizing that the core problem is scheduling.
Planning: Heuristic Search
Another common problem in business is planning. Planning takes many different forms:
- How do I route this arm such that it punches holes in a board as efficiently as possible?
- Can my program ever be in the following configuration?
- How can I go from my bed at home to my desk at work while also running a few errands?
As in scheduling, planning problems have a common thread of representation:
- The state of the world can be stated formally
- There is some world state at the beginning of the problem
- We can describe the desired world state
- We can describe actions and their impact on the world state
- We might be able to estimate the distance from a given state to a goal state
This particular description of planning problems lends itself to discrete state-space search. Consider the punch-routing problem above. There is an initial state of affairs: the arm is in some position and the board has no holes punched into it. There is a goal: the board has the holes punched into it. There are many actions, including moving the joints of the arm and punching a hole. There are many heuristics for this problem, but the simplest is “how many holes remain?”.
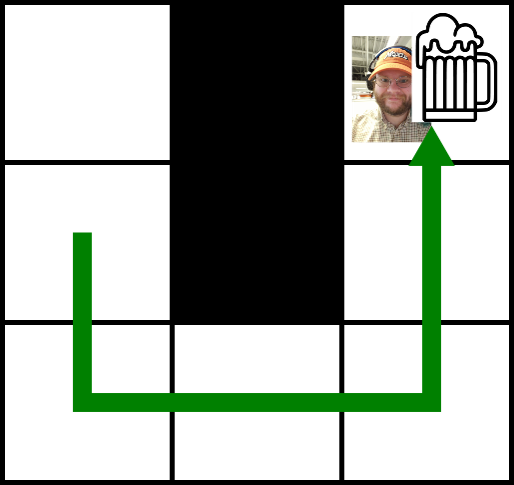
A very concrete example of a search problem is shown above. The state of the world is very simple: where am I, and where is the beer? The actions are motion in a given direction. The goal is for me to be in the same location as the beer.For a small, simple problem like that above, it’s easy to see how to find a solution. As the size of the problem increases, so does the cost of finding a solution. However, the strategies for finding it generally do not. This is the power of search.
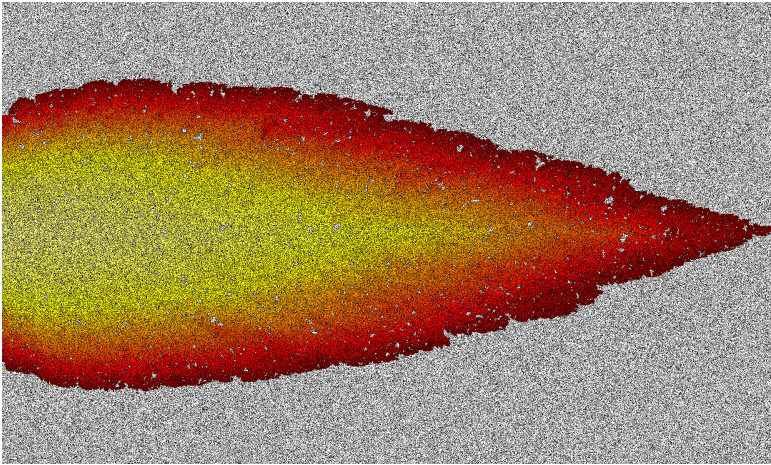
Search works by considering sequences of actions, or plans, in some order. That search algorithm determines that order. The general idea is to look at more complete plans until we find some plan which is complete and desirable. Above we see the order in which A* considers partial solutions. These solutions intend to navigate from the left hand side of the board to the right hand side. Yellow cells were the end point of plans considered early on. Red cells were considered later. Some search orders have special properties. A*’s search order allows us to infer that no cheaper plans exist than the one it finds. Having the provably cheapest solution is useful in many settings.
Machine Learning
Figuring out which group a particular element belongs to has obvious business applications. Will this engaged customer churn? Will this new landing on our website convert into a sale? Is the given customer likely to become an advocate for our product anytime soon. Is this element of our assembly line about to fail? How many trucks in our fleet will need maintenance in the next hundred hours of operation?
The above problems can be solved using a variety of approaches, but supervised learning is a natural fit. Supervised learning requires the following:
- A (large) set of examples to learn from
- The examples must have data describing each
- Relevant information to the problem
- Things like temperature, hours of operation, general telemetry
- These examples must be split into interesting classes and labeled
Supervised learning computes function mapping data to the expected label. It uses the labeled examples and their data to refine the learned function to be as accurate as possible with the given data. While many approaches seek to solve the same problem, they make different trade offs:
- how much computation is needed
- how much and what sort of data is expected
- how scrutable the classification function is
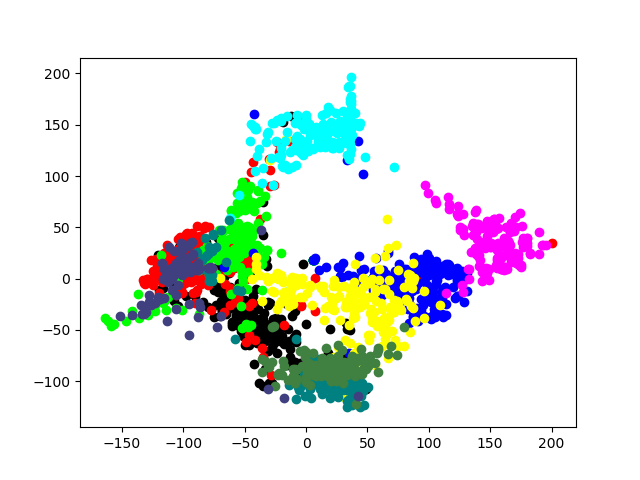
The above image shows ML used to identify handwritten digits. Each dot on the scatter plot represents a different image that a classifier has identified as some digit. Classes, that is the numbers 0 through 9, receive different colors.We compute a mapping from the high-dimensional data of the image down to 2 dimensions. Distances between points in 2D are related to their distance in the larger space. What we see is that the classifier learns that things which are near to one another tend to be of the same class. That is, things which are like one another are often the same digit.
Machine Vision
There is a growing class of software products that span the divide between the digital and the physical world. The most common form of this is needing to get some digital representation of a physical artifact. Examples include:* figuring out the height of a roof from a picture* counting the number of cars in a parking lot from a video feed* producing digital representation of a physical Kanban board.
Machine visions is roughly the field of taking an image and making some sense out of it. There are many sub-fields, each of which a similar thrust: take an image and produce a machinable summary of that image. For example:
- object detection – does the image contain an instance of the object
- scene understanding – what things happen in what order in the following video
- optical character recognition – string is represented in the still image

We can see a demonstration of object detection in the above image. We’re recognizing post-it notes on a whiteboard. A particular sort of post-it note,the lime-green ones, are highlighted by the algorithm. The program actually dose a number of things:
- detect the post it notes
- group them by color
- fix the image such that they’re as rectangular and level
This is just the first step in a larger process: producing a digital representation of a physical kanban board.
Machine vision frequently overlaps with machine learning. Character recognition is a clear examples of this. We distinguish between machine vision and machine learning because the distinction is useful. There are enough common techniques relevant to vision to make the distinction useful:
- edge-detection
- fixing lighting conditions
- handling different orientations
- many others
They have clear analogues in machine learning: feature engineering and data cleaning. They’re specialized enough that it’s useful to use different language to talk about them.
Natural Language Processing
Not all data are similarly easy to machine. Arrays of numbers, selections in drop down lists, and the state of radio buttons are all easy to manipulate as data. Unfortunately, many of our interactions with computers don’t fall into those buckets. Instead, we interact with our world through richer mediums like writing:
- We write blog posts, Wikipedia entries, and product reviews.
- We mention a restaurant we’ve been to in a post of social media
- We live-tweet particularly exciting conference talks and presentations.
Natural language processing is as the name implies, a process for taking human language and presenting it in some machinable form. NLP has techniques that cover the spectrum from cursorily understanding a text to producing a rich machinable representation. Some examples are:
- Analyze a piece of text to understand author sentiment (happy, sad, angry, etc)
- Find references to important topics or locations
- Infer organizational structure from deference in inter-group communication
- Produce a representation of some text in a formal logic
Sometimes natural language processing looks a lot like statistical analysis and machine learning. This is the case for sentiment analysis. It’s also true when we only want to identify what a text is about, rather than what it means. Some applications of NLP require a more nuanced representation of the text. If we intend to read the business section of a newspaper to determine what is happening to the leadership of a particular company, we need to understand what we’re reading. This means diagramming sentences and building machinable representations of their meanings. Selecting the right approach in NLP starts as it does in all other AI settings: having some concrete goal in mind. Once you know what you’d like to accomplish, it’s much easier to find a suitable approach.
Conclusion / Summary
We started off with a question: “What can AI do for me?” Specifically, we started off by talking about how this was the wrong question to ask. Any technology, including AI, works best when you have a concrete problem you’retrying to solve. The problem provides a framework for defining success and evaluation criteria. A problem definition helps you decide the appropriateness of a particular approach.
We went on to look at some common problems that can be addressed with artificial intelligence:
- Scheduling
- Planning
- Categorization
- Producing Machinable Representations of hard-to-understand data
Each of these problems can be tackled with different AI techniques. Being able to identify the core of the problem is the first step to selecting an appropriate technique.
If you recognize problems that you have today in the above vignettes, or if you’re still wondering if AI can help you with your specific problems, please reach out to us. SEP offers a variety of services within the software development life cycle, one of which is identifying opportunities where AI can improve human capabilities or automate previously manual processes.
