
I have a relative that frequently has medical problems. This despite the fact that he’s a healthy young man. His problem is that he has too many names. He’s James-Robert, but depending on whom you ask, you’ll hear him called:
- Jim
- Bob
- Robert
- James
- Jim-Bob
He has five names at least, and that’s before considering the myriad ways of writing them down. His problem isn’t really the number of names he has. It’s that no one can reliably find his medical records.
There are too many inconsistent ways of recording his name. Whenever names make up part of what identifies an individual in a system, he runs into problems. However, names are a natural way of identifying an individual.
It’s unreasonable to ask people to move away from using names as a way of referring to an individual. It’s even more unreasonable to ask Jim-Bob to settle for either James or Robert. If we can’t ask people to change how they identify one another, and we can’t ask people to change how they identify themselves, what can we do?
Record Linkage
In general, this is our problem: how do we determine if two records are linked, that is, they relate to the same entity?
Record linkage can cause problems in a wide variety of different settings. For James-Robert, it’s about finding his medical records, but this problem isn’t limited to the medical domain. It happens everywhere, and the specific impact and mitigation varies by domain and application. In the remainder of this article we’ll focus only on identifying linked records.
Anytime you have an inexact way of entering data you create record linkage issues. It gets worse when you have many places to store information. When you combine that with the following truths:
- Programs almost always store and manipulate information
- Distributed solutions, like the cloud, are popular and growing in popularity
It becomes easy to conclude that many systems have some sort of record linkage issue. While many people are aware that this causes problems, they are not aware that there are programmatic solutions available. Let’s look at how they work.
How Humans Find Related Data
Let’s go back and think about my cousin James-Robert. The list of five alternate names for him wasn’t surprising, was it? That’s because we’ve built up a large set of rules over a lifetime of being human. For example:
- People with hyphenated first names often use one name or the other
- Jim is a shorted version of James (called a hypocorism)
- Bob is a shortened version of Robert
When we apply those rules in combination to “James-Robert”, we produce the above list of names.
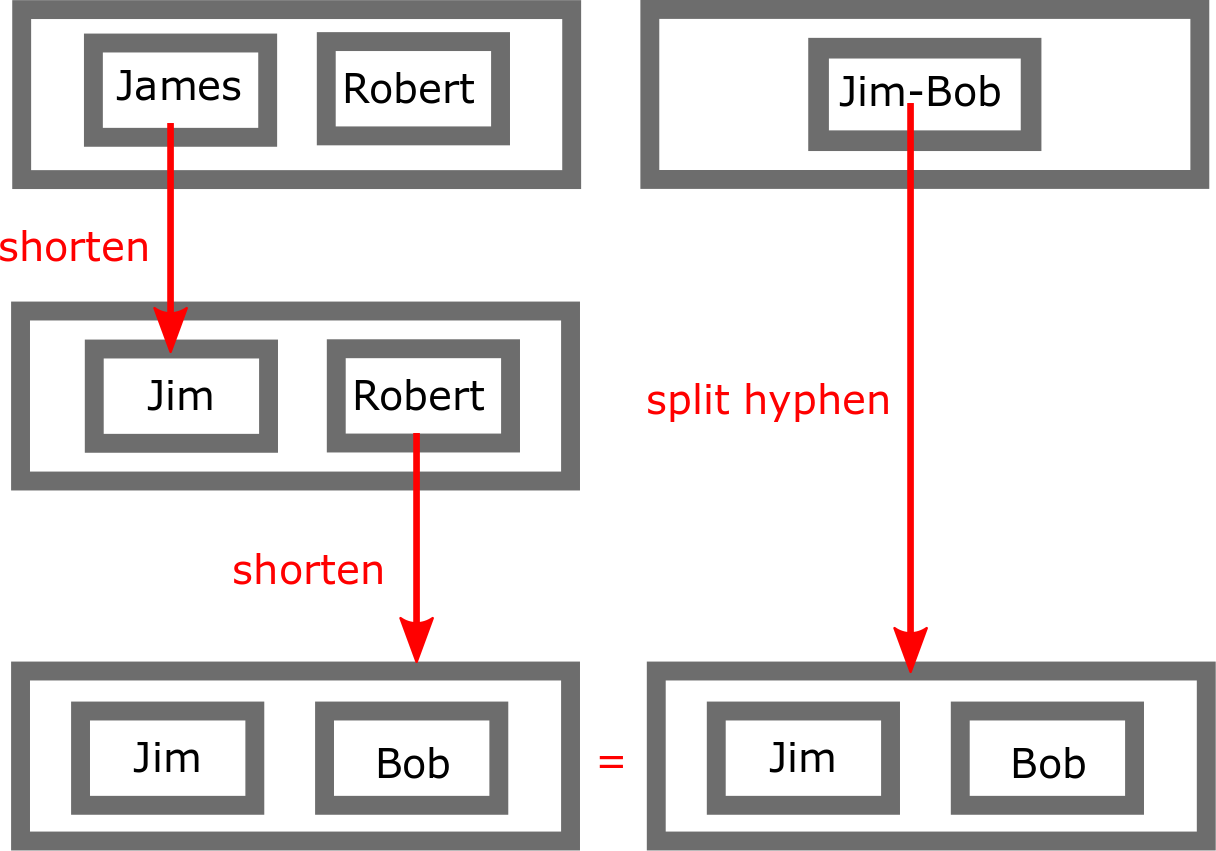
Programmatically solving record linkage problems takes a similar approach. We begin by constructing a set of rules for deriving different representations of the same information. Then, given two entries in a dataset, we use the rules to make them similar. The original difference between entries and the rules applied tell us how likely they are to be related. The example in the above image shows how to transform “James Robert” into “Jim-Bob”.
An Example of a Programmatic Solution
Consider the following hypothetical records representing James-Robert:
- James Robert, 12345 County Line Road, Hope, Indiana
- Jim-Bob, 13245 Co Line Rd, Hope, IN
In most programs, our record would be broken into some sort of structure, such as:
- Name
- Street Address
- City
- State
We can then start to tackle the problem in parts, starting with the name.
Name Alignment
The above images show the steps we go through to compute how related the names of the records are. As we previously discussed, there are several rules we use when transforming names. Here we use two: shortening and splitting hyphens into two names.
We can apply each of these steps in turn until, in this case, our two names are perfectly aligned. This is the main problem of record linkage, and one computers are ideal for: how can we apply the smallest number of rules to make the two names as similar as possible. Record linkage has been studied for decades, and there exist a wide range of tools and techniques to address this problem.
Address Alignment
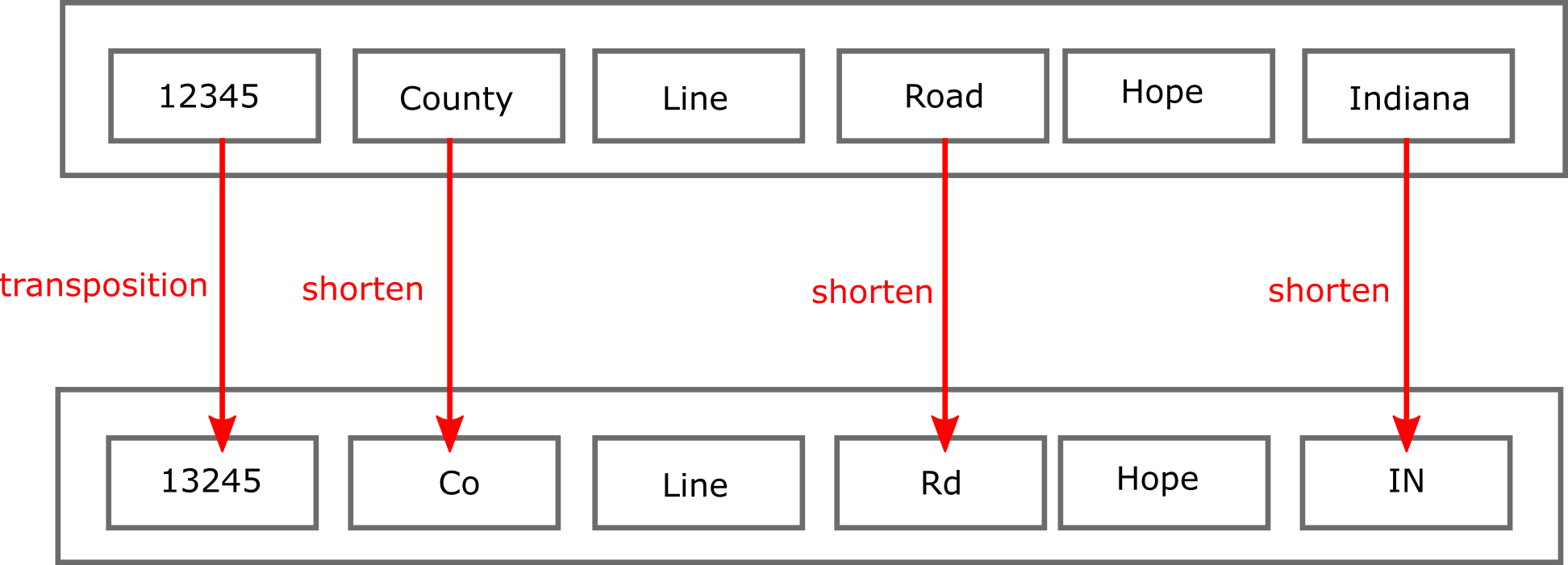
The alignment of addresses is computed similarly, as we see above. For space, we’ve condensed all steps into one and have shown which rules were used on which fragment. As in the name case, the transformation we use most frequently is to shorten. For example: Road and Rd, County and Co, and Indiana and IN.
This example also shows that record linkage can help with more difficult cases. Here, the house number has been entered incorrectly in one case. Someone transposed two digits in the address. This is another class of transformation that record linkage approaches can consider. They help deal with the reality of data entry: humans make typos.
Overall Record Alignment
The actual alignment of the two records would be computed from the alignment of its parts. The name, the address, and any other information would be compared and scored. The intuition being that there is a good chance James-Robert and Jim-Bob are the same person, but that chance increases if both live at the same address.
In general, record linkage approaches consider alignment of the record in parts so that they can consider the alignment of the record as a whole. They use techniques like weighting to decide which parts of the record are most indicative of a link. With enough information and time, they can reliably predict which records are linked.
Conclusion
Your software is likely working with data. People probably work with that data, in fact they probably enter some of it. That information is likely stored in a few different places. It’s likely that you’ve got some record linkage problems in your system.
Record linkage problems are common, but they can also be costly. At the least, they lead to a degraded customer experience. We expect others to have a coherent view of who we are, and unassociated records work against that. In the worst case we can miss critical information about an individual (e.g. allergies).
There are tools out there to help link associated records back together. They help us identify related entries in our dataset. Once we’ve identified related entities, we can act to correct the situation.
Build awesome things for fun.
Check out our current openings for your chance to make awesome things with creative, curious people.
You Might Also Like
