Last Time
Last time we talked about techniques for exchanging processor (and developer) time for reduced will clock time in heuristic search. In other words, we talked about how to use multiple cores on a single machine to solve a problem faster. That worked pretty well, but we noticed that it couldn’t scale beyond the resources available on our desktop. Some problems are truly huge, and we don’t want to be restricted to the resources available on a single machine. The rest of this post shows how you can avoid that limitation.
What’s the difference between distributed search and parallel search?
The difference is unfortunately very little and a very large. It’s few words to state; parallel search and distributed search differ in the number of compute resources used. In parallel computing, you’re using the cores available on a single machine. That can still be a huge number, especially if you’re willing to go to the effort of running your search on some graphics cards. In distributed heuristic search, you’re leveraging multiple computers to solve a problem. In practice, distributed computing allows you to access far mores compute resources than parallel computing.
Memory (and Information Sharing) Are Defining
There’s another difference that’s very simple to state but has a disproportionately large impact on the design and behavior of distributed and parallel algorithms: the memory model is different. In parallel search, you’re often working with a much simpler shared memory model. Parallel algorithms have the luxury of having all workers running on the same device. Sharing information between workers is simple and relatively cheap: worst case, you’re a (memory) bus trip away. In distributed computing, building a shared state is more expensive. Often a network of some variety lies between a worker and its compatriots. Sending data across a network isn’t complicated, but it’s far more expensive than sending memory across a bus or just accessing the same cache in the processor. There are orders of magnitudes of difference in terms of access times, and that necessarily changes how we build distributed algorithms when compared to parallel algorithms.
Some distribution models
I’m going to reiterate the work distribution and communication models we used in the previous post here, for reference sake. Previously, what we wanted to do was allow multiple workers to explore the search tree at the same time. By allowing multiple workers to go in parallel, we could theoretically, and practically, reduce the wall-clock time needed to find a solution to the search problem. In order to parcel the work out effectively, we need to have two classes of processes: workers who expand nodes in the search space and an executor who coordinates the work the other nodes are performing.
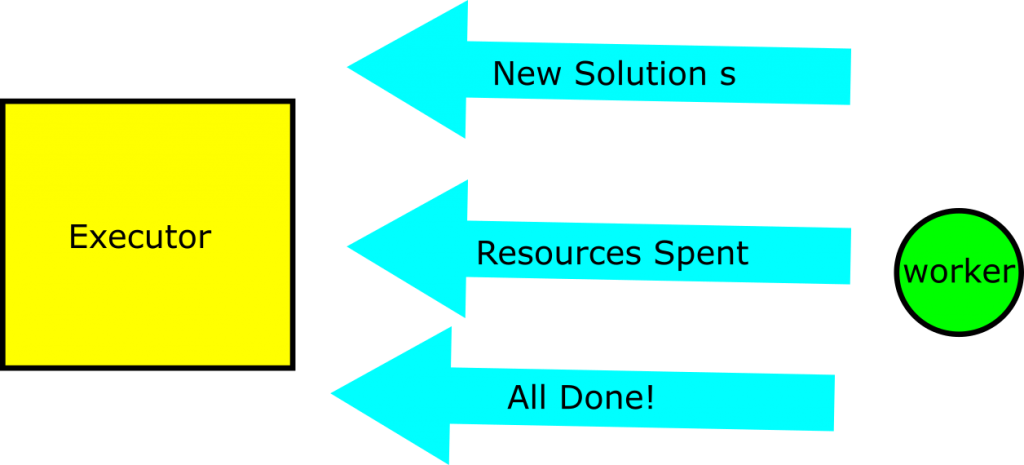
The Parallel Core
Above, and below, we see the messages used to coordinate the efforts of the workers and executors. Above we see those messages sent to the executor by the workers. The most important of these is the message where a worker reports that it has found a new solution to the problem. The goal of search is to find a solution to the problem, so clearly this message is important. Beyond the importance of literally solving the problem as stated, communicating a new solution means we may be communicating a new bound on solution cost. Tighter bounds on solution cost improve overall search performance by allowing us to discard nodes which cannot lead to an improved solution.
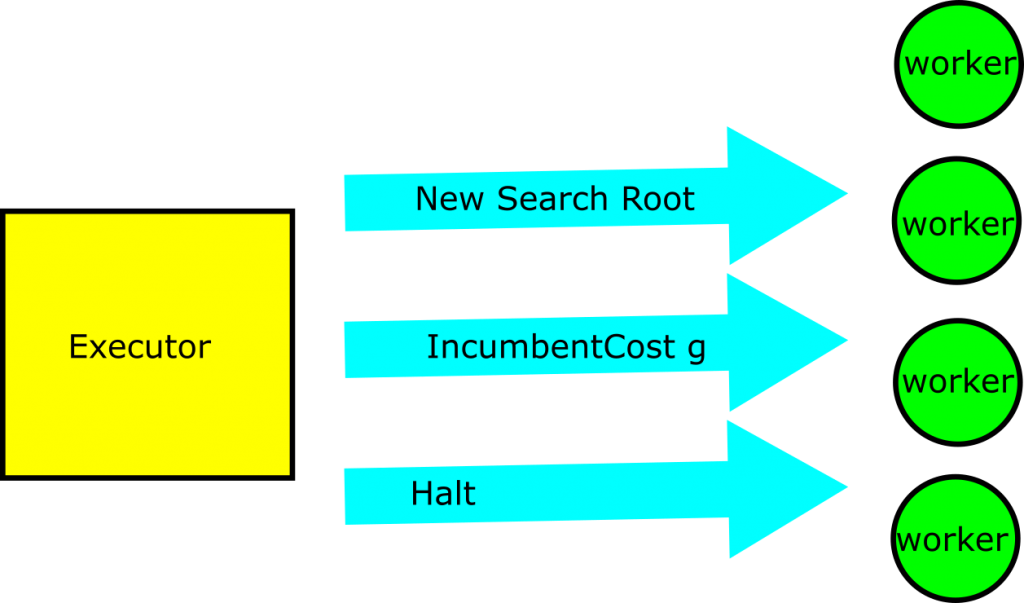
The executor also communicates to the workers. In particular, it communicates new problems to be solved to each of the workers, and it communicates new upper-bounds on solution costs to each of the workers. As we just noted, communicating improved bounds has a large impact on overall search performance. Beyond that, the executor has the very important jobs of handing out work to the workers and telling them when they should stop.
A Direct Translation
It should be noted at this point that there’s nothing that prevents our previous implementation from being used directly in a distributed setting. We communicated between subprocesses in the parallel setting by means of message queues, and that was by design. If those messages queues are handled by throwing structures around in memory, they’ll be quite fast. However, they’re just as well suited to passing structures across a network connection, as we would in the distributed case. Ultimately, this is the model we field for our distributed search system. We’re going to see why by taking a look at the most extreme model for distributed heuristic search and examining it’s weaknesses.
Taking things a little bit too far
Parallel and distributed search are all about slicing up work and distributing it among many processes, then combining the output of those jobs and coming up with a global solution. Many problems contain an ‘atom’ of work, in the sense that it is the smallest unit of work and is indivisible. Heuristic search is no different; the atom of work in search is the node expansion. Expansion encompasses
- Taking a node from the set of all unexplored nodes
- Comparing that node to the current upper bound on solution cost and discarding it or
- Seeing if that node is a goal
- Generating all nodes that can be reached from that node and placing them into the set of unexplored nodes
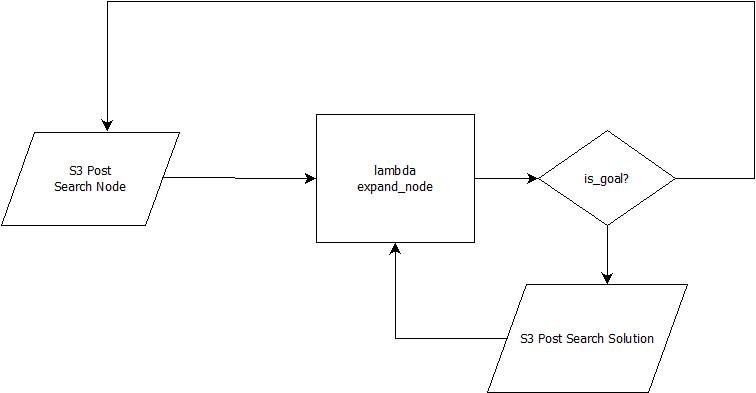
You could have a worker for every node expansion in a distributed search system. The above is a diagram of such a system. The kernel of the system is the rectangle in the center: an AWS lambda that handles a single node expansion. If you’re unfamiliar with lambda, it’s Amazon’s notion of “function as a service”. The basic idea is that if you have some function that’s stateless or effectively stateless, you can define a lambda to scale to arbitrary number of requests to process such a function. Node expansion is roughly such a function, so long as we manage to communicate both the node to be expanded as well as the current incumbent solution to the lambda every time.
Alignment Between “Function as a Service” and Node Expansions
AWS Lambda places pretty tight requirements on compute time and memory consumption. They’re meant for small parcels of work, and node expansion certainly fits the bill. There’s also a nice alignment between how to invoke AWS lambdas and the way search proceeds in general. Lambdas can be started in a variety of ways, one of which is based on S3 events (simple storage service). In effect, we can use S3 as an open list for our distributed search by placing a node back to it every time expansion generates a node (the right-most decision point in the above diagram). Lambda functions are then spun up every time a new node is published to S3.
Monetary Costs
This simple architecture distributes the problem as much as possible, but it’s unusable. It’s prohibitively expensive both in terms of compute time and in terms of actual lucre. Let’s tackle actual pricing first. Compute time for node expansion is negligible, so we’ll just take a look at number of requests. Let’s say that we want to solve that 115,000 city TSP from earlier. There are about 2 x 10^532039 possible solutions in the search space to that problem. Even if we assume we only have to look at 0.05 % of all solutions to compute the optimal answer, we’re talking about evaluation 10^532036 lambdas. The first million lambdas are free, and every million lambdas there after costs 20 cents. This leaves us spending somewhere on the order of 10^532029 dollars on that single computation, which is just a ludicrous sum of money.
Overhead
If we assumed we had infinite money, or that AWS was willing to let us run our code for free, this still wouldn’t be a very good idea. There’s a serious problem with overhead in this setup. Think of everything that happens which isn’t exactly expanding nodes as overhead: sending out messages, processing incoming messages, starting the process up and ending the process. What we’d like is for the work done in part of the distributed system to far outweigh the overhead costs at that node. Single expansions don’t fit this desire; they take next to no time to compute and so their cost is far less than the cost of simply communicating the problem, the known best solution, and the means of generating successor nodes.
Backing off to a more reasonable distribution model
The extreme case of a single expansion at every node won’t work, as we’ve just seen. However, we still want to distribute the problem across multiple compute nodes. To do so, we consider distributing sub-trees to the different compute nodes. This works more or less exactly as it did in the parallel case, as we see below. There’s still an executor. That executor is in charge of communicating new subproblems and incumbent solution costs to each of the worker nodes. Workers still communicate incumbent solutions and that they’ve finished searching their subtree back to the executor. What’s new is the notion of a dispatcher, which tells an executor about a problem to solve and the budget it has for solving it. While you could use other notions of budget, for the remainder of this piece, we’ll think of budget in terms of workers.
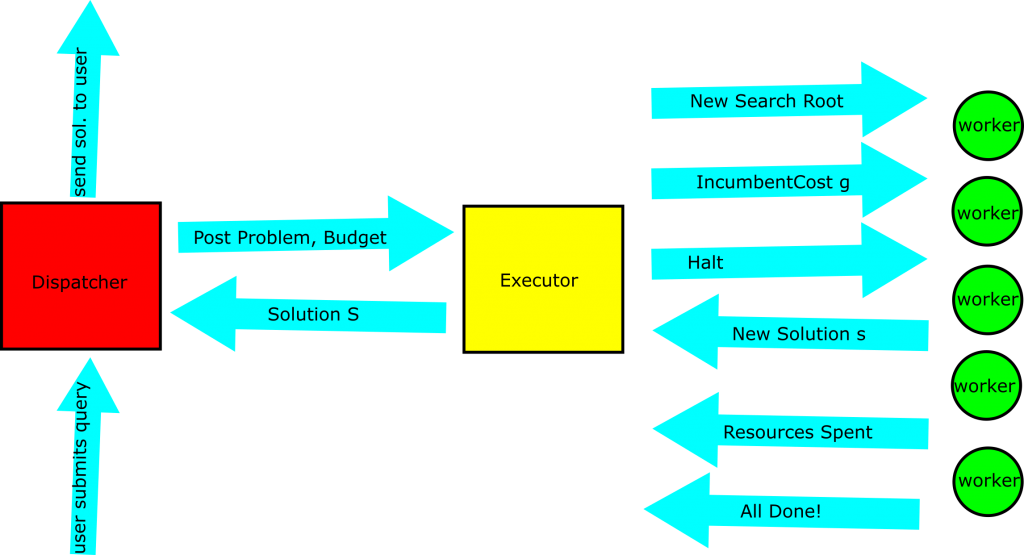
More Specifically…
The process works as follows:
- A user tells the dispatcher about a search problem they want solved.
- The dispatcher tells an executor about a new problem to be solved, and gives it a budget for solving it 1. That budget is primarily in terms of compute nodes
- It could contain a wall-clock time component
- The executor creates worker nodes as the budget allows, giving each a piece of the search space to explore
- Search proceeds as it did in the parallel case, with 1. Workers informing the executor of new solutions
- Executor telling workers about new incumbents for pruning
- When the search space is exhausted, or when the time budget is up, the executor 1. Cleans up all of the workers, tearing them down
- Sends the best found solution to the dispatcher
- falls on its sword
- The dispatcher informs the user of the best found solution, which depending on budget and problem, may be none
I’ve put parts of steps two and three into bold face. This is because these are the steps that cause new compute resources to be allocated. We assume that the executor and workers are constructed on an as-needed basis in a compute cluster somewhere. Up until the problem arrives, we need no computing power to think about the problem. Then, when the user submits the job, we need the executor to start thinking about the problem and how to divide it according to some budget. Once we’ve thought about how to carve the problem up, we need as many compute resources as the budget and executor dictate.
Wait, I don’t own my own compute cluster!
“But Wait!” I hear you cry. “I don’t have my own cluster of compute nodes to submit jobs to!” That’s not a strange position to find yourself in, but that’s ok. You still have access to all of the distributed computing money can buy, so long as you’re willing to deal with the following things:
- Send your data to someone else – This may mean encryption and decryption for sensitive data and problems
- It could mean the use of homomorphic encryption if you’ve got a problem in a few special classes
- Store your data somewhere else – Maybe permanently, maybe temporarily depending on your needs
- You can spend some amount of money to use someone else’s cloud
Who offers access?
There are a variety of vendors that provide computing as a service. You’ve probably stumbled across the term ‘cloud computing’ or the phrase ‘computing in the cloud’. That’s, loosely, what they’re talking about: using someone else’s infrastructure as a service to meet your own needs. Other people have talked about why you might want an on-premise solution or a cloud-based solution to a given problem at great length. From here out, we’re going to assume that you’re not building your own compute cluster and that you’d rather just rent someone else’s for a (relatively) small slice of time.
There are a variety of vendors for cloud services, each with their own set of trade offs. My relatively uninformed opinion is the Amazon’s AWS is one of the most mature options. Google and Microsoft both offer cloud computing services as well. Frankly, for what we’re doing here Digital Ocean is a relatively good fit. We have the following cloud-y actions in the distributed system described above:
- Create a new instance of a compute node
- Create a new instance of an executor node
- Executor -> User Communication
- Worker -> Executor Communication
- Executor -> Worker Communication
Choose, But Choose Wisely
Every cloud computing platform is going to be able to handle those needs. They are, in essence, the building blocks of more complicated and more mature offerings. When selecting a vendor to support this kind of system, you’re making a trade off. You’re basically deciding how much you want to handle your own networking and communication between nodes, and how much you want to let a vendor handle storage and communication for you. Digital Ocean, and vendors like it, is one extreme; I’m going to spin up and tear down my own instances and I’ll manage pointing the message queues at each other. AWS is another extreme; I have the following units of computation, and I want my compute units to subscribe to the following events in a relatively standard publish / subscribe way.
A specific example using AWS
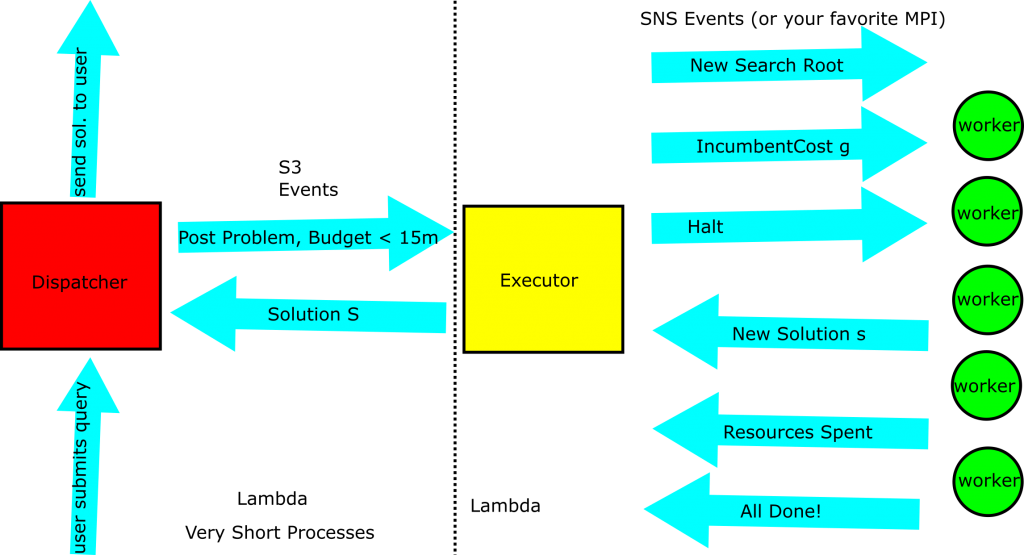
It’s well and good to say than any of the providers could let you do this. Let’s take a look at a specific example: supporting the distributed computation with AWS. Below, we consider how to distribute the search problem using AWS services. We’ve taken the diagram of the distributed system above and labeled the various parts of the diagram with the supporting technologies, as we see below:
- Communication of the problem statement and budget is handled by S3 Events
- Reporting the solution to the user is done by S3 Events (storing the solution as reporting)
- Simple Notification Service is used to support the MailBoxProcessing we used in F# previously
- Lambda supports all of the computation we do here
Why do it like that?
The last two points warrant further discussion. First, we rely on SNS to communicate subproblems, solutions, and incumbent solution cost to the workers. We weren’t enforcing any sort of message delivery order in our previous setup, so we can get away with this. Independent of message delivery order, we are guaranteed to converge on the optimal solution to the search problem. It may effect how much time we spend searching and how many messages we end up sending. If you care about the order in which messages arrive, you can use the simple queuing service instead.
The second is that we’re using lambda for all of our compute needs here. This isn’t a great fit, because lambda has a hard cap on how much compute time you can use on a subproblem (15 minutes as of Apr. 2019). 15 minutes is ages for many computations, but for search it’s a drop in the bucket. Even if we’re talking about using 50 compute nodes, we’re limiting ourselves to problems that can be solved in series within about 12 hours. That said, it is nice for the following reasons:
- Spinning up a lambda on an SNS / SQS event is easy
- Spinning up a lambda on an S3 event is also very easy
- Our approach doesn’t have specific hardware requirements, just “some memory” and “some CPU”
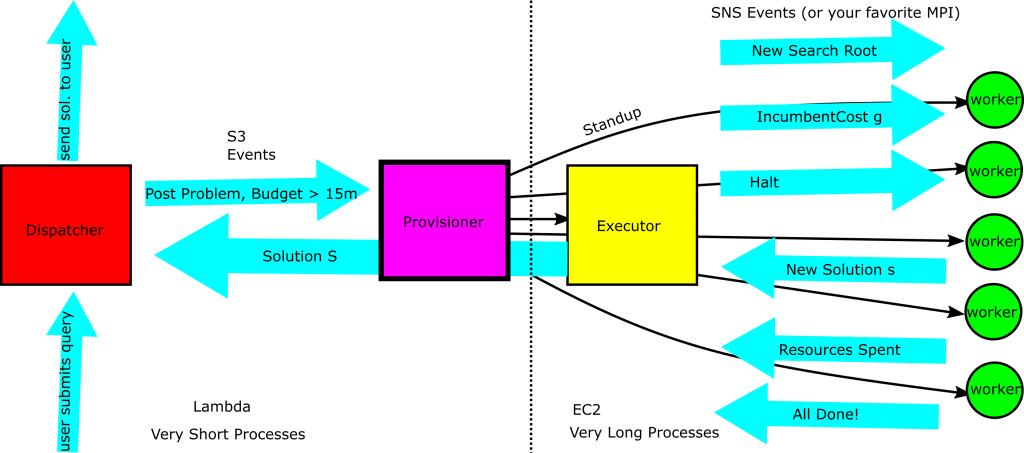
Why not do it that way?
If you felt that the 15 minute cutoff of lambda was too restrictive, you could support the executor and worker nodes on EC2 instances which you configured yourself. It’s still possible to stand up and tear down those nodes programmatically, but you have to do it yourself rather than letting the lambda framework handle it for you. This buys you a little more control over the compute nodes, but it requires you to be more hands on with the process. A hypothetical architecture for doing that is shown below:
Conclusions & Invitations
That was a general recipe for turning parallel heuristic search implementations into distributed heuristic search implementations. Distributed computations can use arbitrary amounts of compute resources, but as we’ve seen, it’s not guaranteed to be enough. For the largest search problems, there just simply aren’t enough resources to ever solve the problem exactly; you’re either going to run out of money to afford resources, or if money is no object, you’ll run out of time before the inevitable heat death of the universe. In spite of these fundamental limitations, heuristic search remains a general and oft applied technique to solving large, difficult, and formally intractable problems.
If you’ve found the series interesting and are eager to hear more, or you just want to pick my brain about related things, there’s an opportunity to do so really soon! I’ll be giving a talk about performing heuristic search in the cloud at IndyCloud 2019. You can see the talk abstract here. I hope to see you there.
